Cet article aborde le processus de prétraitement d’un ensemble de commentaires récupérés d’une vidéo YouTube.
Le but à moyen terme est d’évaluer et de mettre en contraste l’efficacité de la génération d’insights, en la comparant à la méthode traditionnelle de génération de mots-clés basée sur la fréquence d’apparition des mots dans le texte.
Cette approche classique (considérée comme limitée), servira de référence pour évaluer une approche alternative, celle du calcul TF * IDF (Terms Frequency * Inverse Documents Frequency) .
L’objectif final est donc de réaliser une étude comparative de la méthode TF * IDF sur un corpus de taille significative. Malgré l’existence de nombreux tutoriels sur cette méthode, ceux-ci se basent généralement sur de petits échantillons de textes, rendant difficile l’appréciation de son application à grande échelle, en particulier concernant les défis liés au post-traitement d’un corpus volumineux et complexe.
Distribution en fréquence des termes vs TF * IDF
L’analyse des termes basée sur leur distribution en fréquence dans un corpus est une des approches les plus élémentaires pour examiner le contenu textuel. Cette méthode consiste à compter combien de fois chaque occurrence apparaît dans le texte, permettant ainsi de générer le (fameux) nuage de mots clés.
Bien que visuellement attrayante, cette approche présente plusieurs limites quant à son utilité pour extraire des insights pertinents.

Nuage de mots des occurrences les plus fréquentes
Une des principales critiques de cette méthode est sa tendance à survaloriser les termes fréquents qui, souvent, n’apportent pas de valeur ajoutée à l’analyse. Les formes grammaticales tels que « être », « avoir », « faire »…, peuvent dominer le nuage de mots clés, éclipsant ainsi les termes plus significatifs spécifiques au sujet traité.
Bien qu’il soit possible de filtrer ces termes en les excluant de l’analyse, cette démarche reste arbitraire et compromet l’automatisation du processus.
L’approche TF * IDF est une alternative intéressante. Plutôt que de représenter un terme par la fréquence absolue de ses apparitions dans un document (c’est-à-dire son nombre d’occurrences), avec cette méthode l’importance de chaque terme est pondérée en divisant son nombre d’occurrences par le nombre de documents qui contiennent le mot dans le corpus.
Cette méthode repose donc sur deux composantes principales :
- TF (Terms Frequency) : La fréquence d’un terme dans un document.
- IDF (Inverse Document Frequency) : Mesure l’unicité d’un terme dans le corpus. Plus un terme est rare à travers les documents, plus son IDF est élevé, indiquant ainsi une plus grande importance.
Pour appliquer cette méthode efficacement, il est essentiel d’avoir accès à un grand nombre de documents. C’est là qu’intervient l’intérêt du prétraitement du corpus de commentaires. Le processus de formatage et d’extraction des commentaires est conçu de manière à traiter chaque commentaire comme un document individuel.

Data cleaning…
La deuxième étape consiste à développer un script Python pour structurer le corpus. Il est important de noter que cette phase peut s’avérer quelque peu frustrante, étant donné les défis liés à la standardisation de ce type de corpus (commentaires YouTube) en une seule tentative. Un ajustement manuel reste inévitable pour peaufiner les résultats.
J’ai d’ailleurs procédé par itération :
test IF * IDF => résultats => repérage des mots clés sans intérêts (souvent des unités de mesure, des mots ou expression peu académique) => ajustement du corpus => test…
J’ai essayé d’être le plus rigoureux dans cette phase de pré-traitement. Ce corpus servira de base pour de futures expériences, telles que l’analyse de similarité à travers le processus d’embedding et la vectorisation.
Le script est conçu pour accomplir les tâches suivantes :
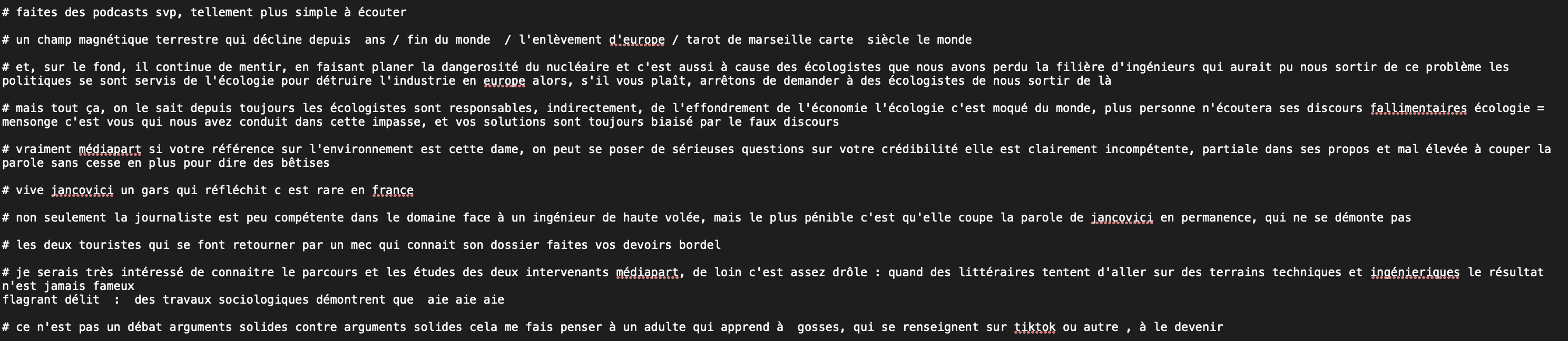
- Charger le fichier de commentaires (environ 1800, je n’ai pas intégré les réponses directes à ces commentaires pour des raisons de simplicité).
- Éliminer les émojis 😉
- Supprimer certains caractères spéciaux.
- Retirer les noms d’utilisateurs, identifiés par @nomdeprofil, bien que certains noms de profil puissent présenter des complications, laissant la possibilité que des résidus subsistent…
- supprimer les dates des commentaires.
- Préfixer chaque commentaire avec le symbole # pour faciliter leur identification en tant que documents distincts lors de l’application du test TF * IDF, un aspect obligatoire pour exécuter le test.
Vous veillerez à adapter le chemin de vos fichiers (import/export).
# Charger le corpus depuis un fichier texte
corpus = load_corpus('/définir_votre_chemin_du_fichier_commentaires.txt')
# Exporter le corpus nettoyé vers un nouveau fichier texte
with open('/définir_votre_chemin_du_fichier_commentaires_nettoyage.txt', 'w', encoding='utf-8') as file: file.write(cleaned_corpus)
import re
# Charger le corpus depuis un fichier texte
def load_corpus(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
corpus = file.read()
return corpus
# Fonction pour prétraiter le texte
def preprocess_text(text):
# Supprimer les caractères spéciaux sauf le #
# text = re.sub(r'[^\w\s#@]', '', text)
# Supprimer les emojis
text = re.sub(r'[\U0001F000-\U0001F9FF]|[\U00010000-\U0010FFFF]|[\u2600-\u26FF\u2700-\u27BF]', '', text)
# Supprimer les noms d'utilisateur et les dates
text = re.sub(r'@[\w-]+\s*|\d{4}-\d{2}-\d{2}\s*', '', text)
# Supprimer les noms d'utilisateur de format spécifique
text = re.sub(r'@[\w-]+(\d+)?\s*', '', text)
# Supprimer les profils de type @n.y.npache2646
text = re.sub(r'@\w+\d+', '', text)
# Supprimer les noms d'utilisateur de format spécifique
text = re.sub(r'@[\w.-]+\s*', '', text)
# Retirer les sauts de ligne après les #
text = re.sub(r'(?<=\S)-\n', '#', text)
# Remplacer les tirets par des # en début de ligne
text = re.sub(r'(?<=\n)-', '#', text)
# Supprimer les chiffres, les deux-points, les points et les points d'exclamation...
text = re.sub(r'[\d"!?_.)(-:$*]', '', text)
return text
# Charger le corpus depuis un fichier texte
corpus = load_corpus('/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/youtube_jancovici_SR.txt')
# Nettoyer le corpus
cleaned_corpus = preprocess_text(corpus)
# Exporter le corpus nettoyé vers un nouveau fichier texte
with open('/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/youtube_jancovici_SR_nettoyer2.txt', 'w', encoding='utf-8') as file:
file.write(cleaned_corpus)
Lemmatisation du texte et « stopword »
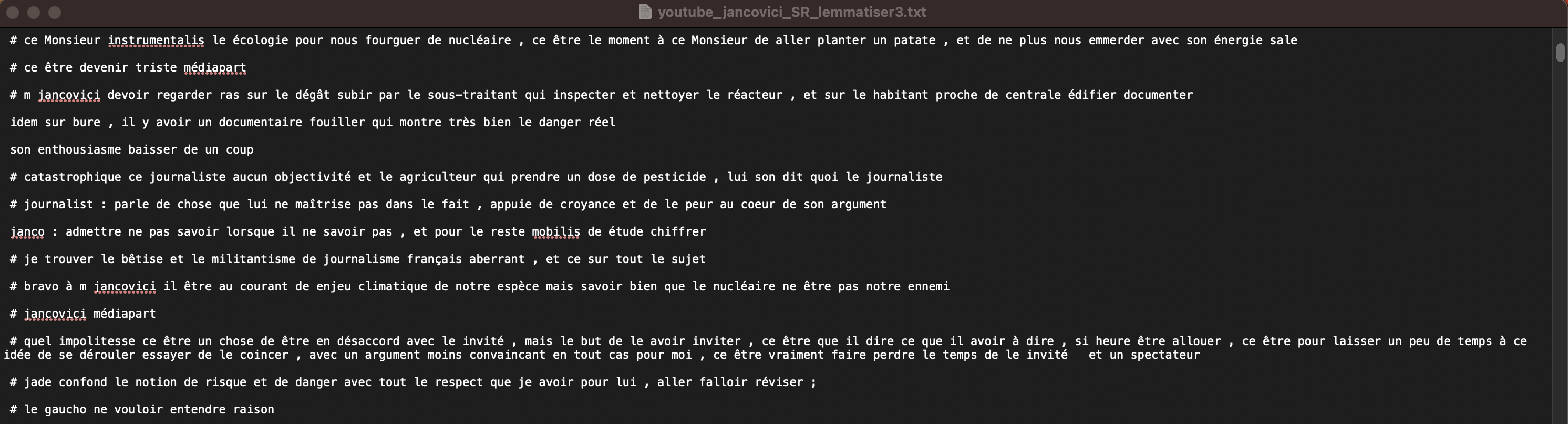
La troisième étape implique la lemmatisation du texte.
L’organisation séquentielle des scripts est avantageuse car elle délimite clairement les différentes phases de traitement, offrant ainsi la possibilité de revenir aisément à n’importe quelle version des fichiers texte précédemment créés.
À ce stade, vous devriez disposer de plusieurs fichiers :
- Le fichier texte original des commentaires.
- Le fichier texte des commentaires après nettoyage.
# pip install spacy
# python -m spacy download fr_core_news_sm
import spacy
# Charger le modèle de langue SpaCy pour le français
nlp = spacy.load("fr_core_news_sm")
# Supprimer l'espace devant chaque # en début de ligne
def remove_space_before_hashtag(text):
return re.sub(r'(?<=\n) #', '#', text)
# Fonction pour lemmatiser le texte
def lemmatize_text(text):
# Traiter le texte avec SpaCy
doc = nlp(text)
# Extraire les lemmes de chaque token
lemmatized_text = " ".join([token.lemma_ for token in doc])
return lemmatized_text
# Charger le corpus nettoyé depuis un fichier texte
with open('/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/youtube_jancovici_SR_nettoyer2.txt', 'r', encoding='utf-8') as file:
corpus = file.read()
# Lemmatiser le corpus
lemmatized_corpus = lemmatize_text(corpus)
# Exporter le corpus lemmatisé vers un nouveau fichier texte
with open('/Users/stephanemeurisse/Documents/DataSet/Jancovici_nucleaire/youtube_jancovici_SR_lemmatiser3.txt', 'w', encoding='utf-8') as file:
file.write(lemmatized_corpus)
L’utilisation du script est très simple. Avant de commencer, vous devez installer dans le terminal de votre éditeur de code la bibliothèque Spacy ainsi que son module pour la langue française.
pip install spacy
python -m spacy download fr_core_news_sm
En utilisant le script vous entreprendrez la lemmatisation du texte à l’aide de la bibliothèque Spacy, (la librairie NLP du pauvre 😉
Je suis parfois un peu surpris par la lemmatisation du texte généré avec Spacy…






Laisser un commentaire