Historique du test LDA
Le Latent Dirichlet Allocation (LDA) est un modèle probabiliste basé sur l’idée que les documents sont constitués d’une combinaison de topics, et que chaque topic est caractérisé par une distribution de mots. LDA appartient à la catégorie des modèles d’apprentissage non supervisé.
Dans le contexte du traitement automatique du langage naturel, le test LDA est utilisé pour découvrir les topics latents présents dans un grand corpus de texte.
Par exemple, un topic sur « l’économie » pourrait être caractérisé par des mots tels que « marché », « finance », « investissement », tandis qu’un topic sur « la santé » pourrait inclure des mots comme « médecin », « hôpital », « traitement ». Il est important de noter que les topics sont des distributions probabilistes de mots et ne sont pas définis a priori mais découverts par le modèle à partir des données.
L’objectif est de modéliser un document comme un mélange de topics et d’assigner une probabilité à chaque mot dans un topic. Cela permet de regrouper les documents en clusters basés sur leurs sujets « dominants », facilitant ainsi la recherche d’information (DataMining).
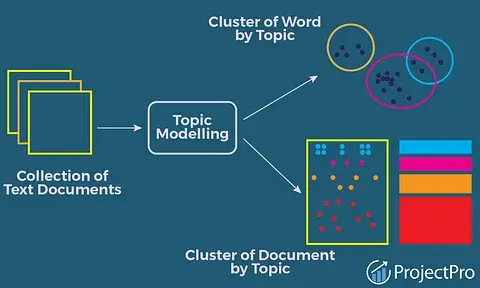
L’apprentissage non supervisé, auquel appartient LDA, diffère de l’apprentissage supervisé en ce sens qu’il n’utilise pas de données étiquetées. Au lieu de cela, il essaie de découvrir des structures cachées dans les données d’entrée. Cela signifie que le test LDA identifie des regroupements de mots (topics) qui apparaissent fréquemment ensemble dans le corpus de documents. LDA se base sur la modélisation probabiliste.
Prétraitement du corpus
Voici la démarche que j’ai suivie dans mon exemple : je me suis intéressé à l’extraction d’articles de presse depuis Europress, filtrés selon deux mots-clés :
- Santé & « intelligence artificielle »
- Éducation & « intelligence artificielle »
- Journalisme & « intelligence artificielle »
- Littérature & « intelligence artificielle »
- Photographie & « intelligence artificielle »
- Cinéma & « intelligence artificielle »
- Musique & « intelligence artificielle »
Cette approche a permis d’extraire environ 1026 articles sur un an à travers plusieurs quotidiens (Le journal Le Monde, Le Figaro, Les Echos, La Croix, La Tribune, Libération, L’Opinion). À cette étape, j’ai utilisé le filtre mis à disposition par Europress pour cibler les journaux nationaux français. Cette méthode permet de constituer rapidement un corpus, bien qu’une approche plus détaillée semble incontournable.
Par la suite, j’ai reconstruit un corpus global en concaténant les articles thématiques les uns à la suite des autres (à la mano), ce qui a pris environ 2 minutes.
J’ai choisi de traiter chaque article de presse comme une entité distincte, en utilisant un marqueur spécial « ****« , pour identifier et séparer les documents. Toutefois, l’analyse LDA concaténera ces documents pour former un seul et unique corpus.
Comme toujours, la préparation des données avant l’application du test est primordiale. Comme on le verra, ce test se déroule en deux étapes. Après avoir traité le corpus avec la bibliothèque SpaCy, dans le but de lemmatiser le texte et d’éliminer les verbes (qui reviennent trop fréquemment et n’apportent pas de sens significatif à l’analyse). Ainsi, les fonctions de prétraitement (dans mon cas) visent à :
- Exclure les mots vides (stop words)
- Exclure les verbes pour ne retenir que les noms, les noms propres et les adjectifs
Il s’agit d’un choix arbitraire à effectuer en fonction de l’objectif de votre analyse. Par la suite, une fois l’analyse lancée, vous pourrez juger s’il est nécessaire d’affiner le filtrage à l’aide des fonctions no_above et no_below.
def preprocess_text(text):
doc = nlp(text)
# Filtrer les tokens pour ne garder que ceux qui ne sont pas des stop words,
# qui sont alphabétiques, et qui sont des noms (NOUN), des adjectifs (ADJ) ou des noms propres (PROPN).
tokens = [token.lemma_.lower() for token in doc if token.is_alpha and not token.is_stop and token.pos_ in ['NOUN', 'ADJ', 'PROPN']]
return tokens
A noter que vous pouvez décommenter la fonction de prétraitement classique dans le script qui intègre l’ensemble du vocabulaire (sauf les stopwords)
# Fonction pour le prétraitement des textes
# def preprocess_text(text):
# Étape 1: Traiter le texte avec le modèle SpaCy pour le français
# Cela permet d'analyser le texte et de le diviser en "tokens"
# doc = nlp(text)
# Étape 2: Initialiser une liste vide pour stocker les lemmes filtrés et normalisés
# filtered_lemmas = []
# Étape 3: Parcourir chaque token dans le document traité
# for token in doc:
# Étape 4: Vérifier si le token est alphabétique et n'est pas un stopword
# if token.is_alpha and not token.is_stop:
# Étape 5: Récupérer le lemme du token, le convertir en minuscules et l'ajouter à la liste
# lemma = token.lemma_.lower()
# filtered_lemmas.append(lemma)
# Étape 6: Retourner la liste des lemmes filtrés et normalisés
# return filtered_lemmas
Une seconde étape, après avoir réalisé une première exécution du test LDA, consiste à ajuster le paramétrage du corpus à l’aide des options no_below et no_above. Ces paramètres offrent la possibilité d’optimiser l’analyse en « affinant » le corpus. De même, le nombre de topics à extraire, déterminé lors de la première analyse, peut être ajusté ultérieurement.
En résumé, à la suite de vos premiers résultats, vous aurez la possibilité de modifier trois aspects clés :
- Le nombre de topics à extraire
- Le paramètre no_below
- Le paramètre no_above
Création des bigrammes
La bibliothèque Gensim permet de calculer les bigrammes. Il est également possible de créer des bigrammes avec la bibliothèque NLTK, mais la librairie Gensim, est optimisée pour le traitement de grands volumes de texte. A noter que les bigrammes sont intégrés à l’analyse LDA, cela fait partie du prétraitement du corpus. Pour chaque paire de mots consécutifs, Gensim calcule un score qui mesure la force de leur association (score de cooccurrence ).
Les bigrammes sélectionnés sont ensuite formés en joignant les deux mots avec un underscore (par exemple : « intelligence_artificielle« ).
# Création des bigrammes phrases = Phrases(texts, min_count=5, threshold=10) bigram = Phraser(phrases) texts_with_bigrams = [bigram[text] for text in texts]
Ce processus transforme le corpus original en incorporant ces bigrammes comme de nouvelles entités dans le texte. Vous retrouverez la liste des bigrammes dans un fichier csv quand vous lancerez l’analyse. Cette liste s’affiche également dans le terminal de votre éditeur de code.
Choix du nombre de topics
Le nombre de thèmes (k) à identifier dans le corpus lors de l’analyse LDA doit être spécifié préalablement. Il n’existe pas de stratégie rigoureuse pour déterminer le nombre optimal de thèmes à extraire; souvent, cette décision relève d’une approche par « tâtonnement ».
# Application de LDA # Ici, vous pouvez modifier le nbre de topics lda_model = LdaModel(corpus, num_topics=12, id2word=dictionary, passes=15) # Ici, num_topics=x
Lancement de l’analyse
L’analyse se réalise à travers une démarche d’expérimentation et de tâtonnement. Ainsi, il est recommandé de commencer par une analyse avec des paramètres standard, y compris le nombre de sujets ainsi que les seuils no_below et no_above.
Bien que vous puissiez poursuivre vos analyses sans changer ces paramètres, ajuster ces valeurs peut enrichir l’exploration textuelle. L’objectif est de découvrir des insights significatifs; cette méthode ne vise pas à confirmer une hypothèse préalable. Le test LDA est un outil conçu pour vous aider à identifier des thèmes au sein d’un large corpus textuel.
#pip install matplotlib
#pip install pandas --upgrade
#pip install spacy
#python -m spacy download fr_core_news_lg ou sm
#pip install gensim
#pip install pyldavis
#pip install WordCloud
#pip install numpy
import spacy
import csv
import pandas as pd
from gensim import corpora
from gensim.models.ldamodel import LdaModel
from gensim.models.phrases import Phrases, Phraser
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
# Chargement du modèle SpaCy pour le français
nlp = spacy.load('fr_core_news_lg')
# Fonction pour le prétraitement des textes
# def preprocess_text(text):
# Étape 1: Traiter le texte avec le modèle SpaCy pour le français
# Cela permet d'analyser le texte et de le diviser en "tokens"
# doc = nlp(text)
# Étape 2: Initialiser une liste vide pour stocker les lemmes filtrés et normalisés
# filtered_lemmas = []
# Étape 3: Parcourir chaque token dans le document traité
# for token in doc:
# Étape 4: Vérifier si le token est alphabétique et n'est pas un stopword
# if token.is_alpha and not token.is_stop:
# Étape 5: Récupérer le lemme du token, le convertir en minuscules et l'ajouter à la liste
# lemma = token.lemma_.lower()
# filtered_lemmas.append(lemma)
# Étape 6: Retourner la liste des lemmes filtrés et normalisés
# return filtered_lemmas
def preprocess_text(text):
doc = nlp(text)
# Filtrer les tokens pour ne garder que ceux qui ne sont pas des stop words,
# qui sont alphabétiques, et qui sont des noms (NOUN), des adjectifs (ADJ) ou des noms propres (PROPN).
tokens = [token.lemma_.lower() for token in doc if token.is_alpha and not token.is_stop and token.pos_ in ['NOUN', 'ADJ', 'PROPN']]
return tokens
# Lecture des données et prétraitement
file_path = '/ici/chemin/de/votre/corpus/corpus-ia.txt'
articles = []
with open(file_path, 'r', encoding='utf-8') as file:
article_content = []
for line in file:
if line.startswith('****'):
if article_content:
preprocessed_text = ' '.join(preprocess_text(" ".join(article_content)))
articles.append(preprocessed_text)
article_content = []
else:
article_content.append(line.strip())
if article_content:
preprocessed_text = ' '.join(preprocess_text(" ".join(article_content)))
articles.append(preprocessed_text)
# Affichage du nombre d'articles traités
print(f"Nombre d'articles traités : {len(articles)}")
# Transformation des articles en listes de mots pour la détection des bigrammes
texts = [article.split() for article in articles]
# Création des bigrammes
phrases = Phrases(texts, min_count=5, threshold=10)
bigram = Phraser(phrases)
texts_with_bigrams = [bigram[text] for text in texts]
# Affichage des bigrammes trouvés pour contrôle
bigrams_found = set()
for text in texts_with_bigrams:
for word in text:
if '_' in word:
bigrams_found.add(word)
print("Bigrammes trouvés dans le corpus:")
for bigram in sorted(bigrams_found):
print(bigram)
# Exportation des bigrammes trouvés en CSV
bigram_path = '/ici/chemin/de/votre/dossier/de/sortie/LDA/bigrammes_trouves.csv'
with open(bigram_path, 'w', newline='', encoding='utf-8') as csvfile:
bigram_writer = csv.writer(csvfile)
bigram_writer.writerow(['Bigramme'])
for bigram in sorted(bigrams_found):
bigram_writer.writerow([bigram])
# Création du dictionnaire et du corpus pour LDA, utilisant les textes avec bigrammes
dictionary = corpora.Dictionary(texts_with_bigrams)
corpus = [dictionary.doc2bow(text) for text in texts_with_bigrams]
####### calcul optimal du filtrage
# Supposons que 'dictionary' est votre dictionnaire Gensim créé à partir du corpus
word_frequencies = [dictionary.dfs[word_id] for word_id in dictionary.keys()]
# Visualisation de la distribution des fréquences de mots
plt.figure(figsize=(10, 6))
plt.hist(word_frequencies, bins=100, log=True)
plt.title("Distribution des fréquences de mots")
plt.xlabel("Fréquence du mot")
plt.ylabel("Nombre de mots")
plt.show()
# Calcul des statistiques pour déterminer les seuils
print(f"Moyenne de fréquence: {np.mean(word_frequencies):.2f}")
print(f"Médiane de fréquence: {np.median(word_frequencies):.2f}")
print(f"90e percentile: {np.percentile(word_frequencies, 90):.2f}")
print(f"10e percentile: {np.percentile(word_frequencies, 10):.2f}")
####### fin
# Application du filtrage pour éliminer les mots trop rares ou trop fréquents
# no_below -> vise à exclure (ou non) les termes rares (valeurs 0 -> 1)
# selon votre objectif cette valeur peut rester par defaut à 0
# no_allow -> vise à réduire les mots trop fréquent
dictionary.filter_extremes(no_below=0, no_above=0.6) # Filtrage par fréquence
# Création du corpus à partir des textes avec bigrammes
corpus = [dictionary.doc2bow(text) for text in texts_with_bigrams]
# Application de LDA
num_topics = 12 # Définissez le nombre de topics que vous souhaitez extraire
lda = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=15)
# Préparation des données pour la visualisation LDA
lda_display = gensimvis.prepare(lda, corpus, dictionary, sort_topics=False) # Utilisation de l'alias 'gensimvis'
# Sauvegarde de la visualisation
visualization_path = '/ici/chemin/de/votre/dossier/de/sortie/LDA/lda_visualization.html'
pyLDAvis.save_html(lda_display, visualization_path)
# Affichage du nombre d'articles traités
print(f"Nombre d'articles traités : {len(articles)}")
# Exportation des résultats en CSV
topics_data = [{'Topic': topic_id+1, 'Word': word, 'Probability': round(prob, 4)}
for topic_id, topic_words in lda.show_topics(formatted=False, num_topics=num_topics, num_words=10)
for word, prob in topic_words]
df_topics = pd.DataFrame(topics_data)
csv_path = '/ici/chemin/de/votre/dossier/de/sortie/LDA/lda_topics.csv'
df_topics.to_csv(csv_path, index=False)
print(f"Les topics ont été sauvegardés dans {csv_path}")
#### nuage de mots
# Extraction des mots-clés pour chaque topic et leurs poids
topics = lda.show_topics(formatted=False, num_topics=num_topics, num_words=20)
# Création d'un nuage de mots pour chaque topic
for topic_num, topic_words in topics:
plt.figure(figsize=(10, 7)) # Définir la taille de la figure
plt.title(f"Topic #{topic_num + 1}") # Titre du nuage de mots
# Préparer les données pour le nuage de mots : convertir la liste de tuples en un dictionnaire
dict_words = dict(topic_words)
# Génération du nuage de mots
wordcloud = WordCloud(width=800, height=560, background_color='white').generate_from_frequencies(dict_words)
# Affichage du nuage de mots
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off") # Cacher les axes
plt.show()
# Enregistrement des nuages de mots, si nécessaire
wordcloud.to_file(
f"/ici/chemin/de/votre/dossier/de/sortie/LDA/topic_{topic_num + 1}_wordcloud.png")
Les paramètres no_bolow et no_allow
La fonction de filtre dans Gensim sert à filtrer les tokens (mots) avant la création du corpus pour les modèles de topics comme LDA. Après avor ajusté les valeurs vous devrez relancer une analyse LDA. (Ne pas oublier de changer le répertoire de sauvegarde des fichiers autrement vous allez écraser les données de votre première analyse).
# Application du filtrage pour éliminer les mots trop rares ou trop fréquents # no_below -> vise à exclure (ou non) les termes rares (valeurs 0 -> 1) # selon votre objectif cette valeur peut rester par defaut à 0 # no_allow -> vise à réduire les mots trop fréquent dictionary.filter_extremes(no_below=0, no_above=0.6) # Filtrage par fréquence
Voici ce que font les paramètres no_below et no_above :
no_below: Par exemple, si no_below=5, tous les mots qui apparaissent dans moins de 5 documents seront ignorés. Cela est utile pour enlever les mots rares qui n’ont peut-être pas beaucoup de pouvoir discriminatoire en termes de topics.
Si vous laissez la valeur no_below = 0, tous les mots rare seront conservés.
no_above: les valeurs de ce paramètres sont compris entre 0.0 et 1.0, représentant un pourcentage (0% à 100%) des documents. Une valeur de 1.0 (ou 100%) signifie que vous ne filtrez aucun mot en fonction de leur fréquence maximale à travers les documents. Chaque mot, peu importe sa fréquence, sera conservé.
j’ai essayé de trouver une logique pour paramétrer ces deux valeurs. L’analyse des percentiles serait peut être une solution « rationnelle ».

Dans cet exemple ci-dessus les statistiques fournissent un aperçu de la distribution des fréquences des mots dans le corpus.
Médiane de fréquence (2.00) : Une médiane de 2 signifie que la moitié des mots apparaît deux fois ou moins.
90e percentile (18.00) : Cela signifie que 90% des mots apparaissent 18 fois ou moins. Seuls 10% des mots dépassent cette fréquence.
10e percentile (1.00) : Cela indique que 10% des mots apparaissent une fois ou moins.
Pour la valeur no_below : Étant donné que la médiane de fréquence est de 2, cela indique que de nombreux mots apparaissent très rarement. Pour réduire le bruit et concentrer l’analyse sur des mots plus pertinents, il est possible d’envisager de fixer no_below à une valeur légèrement supérieure à la médiane, par exemple à 3 ou 4. Cela exclura les mots qui apparaissent dans très peu de documents et qui sont peu susceptibles de contribuer de manière significative aux sujets trouvés par LDA. Toutefois si la rareté des termes est essentiels, laissez la valeurs à 0.
Pour la valeur no_above : Étant donné que le 90e percentile est de 18, cela signifie que seulement 10% des mots apparaissent plus de 18 fois dans l’ensemble du corpus. Une valeur courante pour no_above est de 0.5 ou 0.6, ce qui exclut les mots qui apparaissent dans plus de 50% à 60% de tous les documents.
La représentation graphique
Le graphique produit par l’analyse représente les 30 termes de chaque topics.
- Barre Bleue (Estimated term frequency within the selected topic): Indique la fréquence globale du terme dans l’ensemble du corpus. Cela montre à quel point le terme est commun ou fréquent dans tous les documents, indépendamment de tout topic spécifique.
- Barre Rouge (Overall term frequency) : Représente la fréquence estimée du terme au sein du topic sélectionné. Cela indique à quel point le terme est pertinent ou spécifique à ce topic particulier, en opposition à sa présence dans l’ensemble du corpus.
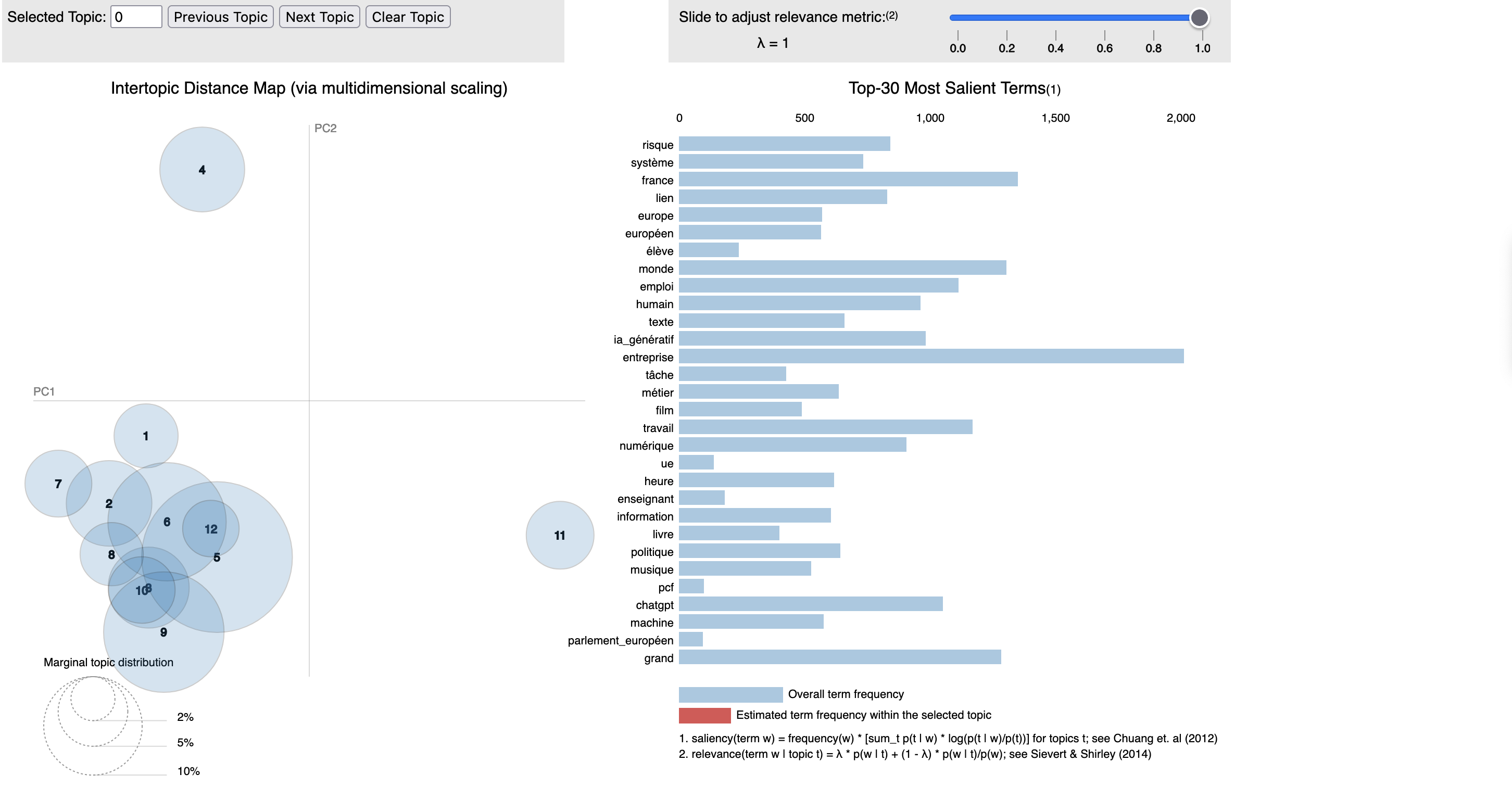
La métrique de pertinence dans l’interface de visualisation de pyLDAvis (en haut à droite du graphique) est un moyen de filtrer les mots clés qui apparaissent dans chaque topic pour mieux comprendre les thèmes représentés dans le corpus. Cette métrique ajuste l’équilibre entre la fréquence des mots et leur spécificité ou exclusivité par rapport à ce topic.
Lorsque la barre de réglage est déplacée vers la droite (valeur plus élevée), l’algorithme favorise des mots qui sont plus spécifiques à un topic donné. Ces mots peuvent être moins fréquents mais sont plus susceptibles d’être distinctifs pour ce topic particulier. Cela peut aider à identifier les termes qui définissent le mieux le caractère unique d’un topic.
Lorsque la barre de réglage est déplacée vers la gauche (valeur plus faible), la visualisation met davantage l’accent sur les mots les plus fréquents dans le topic, indépendamment de leur spécificité. Cela peut inclure des mots qui sont communs à plusieurs topics mais qui apparaissent fréquemment dans le topic en question.






Laisser un commentaire