L’intelligence artificielle (IA) fascine et intrigue. Au cœur de cette révolution technologique, ChatGPT de OpenAI, basé sur l’architecture GPT-4, représente pour certains une « imposture » et pour d’autres une innovation majeure.
IA Faible (Intelligence Artificielle Faible) vs IA Forte (Intelligence Artificielle Forte)
L’IA faible est conçue pour exécuter une tâche spécifique dans un domaine particulier, basée sur des règles et des algorithmes pré-programmés comme les assistants vocaux les assistants vocaux (Siri ou Alexa…), mais également le filtrage et le tri de vos mails (spam, phishing, boite de réception…)
L’IA Forte est conçue pour être aussi intelligente que l’être humain et capable de résoudre des problèmes complexes dans n’importe quel domaine. Capable d’apprendre, de raisonner et de comprendre le monde de manière similaire à l’être humain. Théoriquement, elle serait capable d’abstraction et de raisonnement. A ce jour, l’IA forte n’existe pas sauf dans le domaine de la recherche fondamentale ou le cinéma 😉.
GPT fait parti des IA faible. Le modèle de langage de GPT n’a aucune compréhension de ce que vous lui demandez et de ses réponses.

GPT, signifie « Generative Pre-trained Transformer », est un modèle de langage développé par OpenAI.
Comme son nom l’indique, GPT est un modèle génératif (IA générative), ce qui signifie qu’il génère du texte. Il est capable de répondre à des questions, de rédiger des textes, de traduire des langues, et même de créer du code informatique.
Comment ChatGPT construit ses réponses ?
ChatGPT est un modèle de traitement du langage développé par OpenAI. Son fonctionnement est basé sur une architecture de réseau neuronal appelée « Transformateur », spécifiquement la version GPT (Generative Pre-trained Transformer).
Voici les principales de fonctionnement :
Pré-entraînement : Avant d’être disponible pour interagir, GPT est entraîné sur un vaste ensemble de données textuelles. Ces données incluent des livres, des articles, des sites Web, et d’autres formes de textes écrits.
L’objectif de cet entraînement est de permettre à GPT de comprendre et de générer du langage « naturel ».
Traitement de la requête : Lorsqu’un utilisateur poste une question à GPT4, ce dernier traite votre texte pour comprendre son sens notamment en analysant la structure grammaticale, le vocabulaire, le contexte.
le modèle de langage de GPT-4 est construit avec une architecture de réseau de neurones appelée « Transformer« . Chaque couche de ce réseau effectue des opérations complexes pour traiter et générer du langage. Au sein des couches de « Transformer », il y a des mécanismes d’attention qui permettent au modèle de se concentrer sur différentes parties d’une phrase ou d’un texte lors de la génération de réponses.
Génération de la réponse : En croisant les informations apprises pendant le pré-entraînement et les détails spécifiques de votre requête, GPT 4 génère une réponse. GPT sélectionne les mots et les phrases qui correspondent le mieux à la réponse requise, tout en veillant à ce que la réponse soit cohérente.
GPT n’a aucune compréhension de votre question et de sa réponse, c’est un calcul statistique croisant le contexte de votre requête et les différentes données qu’il a à sa disposition (base d’entrainement).
Prenons un premier exemple :
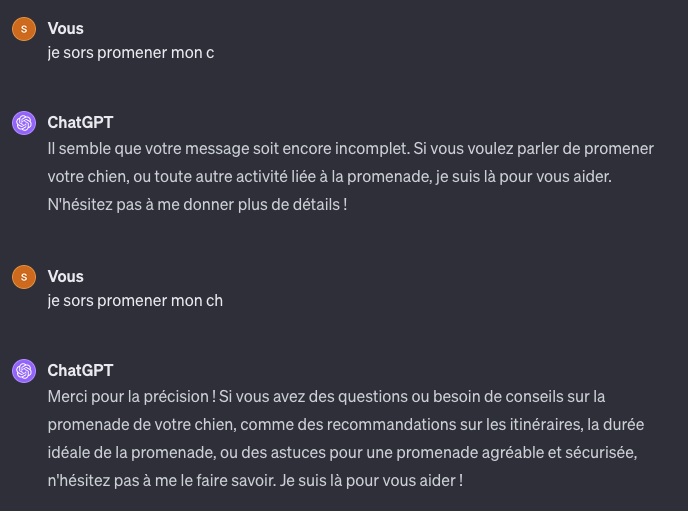
« je sors promener mon c« , volontairement je ne complète pas mon affirmation pour observer comment GPT4 va compléter la suite de ma phrase. Je dois faire un second essai en ajoutant une consonne à ma phrase.
« je sors promener mon ch » à ce stade d’un point de vue sémantique, GPT4 à le choix pour compléter ma phrase entre « chien » , « chat » … « chiot » … et tous les noms d’animaux de compagnie qui commencent par « ch« .
Sa réponse montre qu’il à fait un choix en sélectionnant le terme « chien » car il est fort probable que dans sa base d’entrainement ce terme est plus fréquemment associé à ma phrase.
Deuxième exemple :
« Simone Veil a été présidente« .
Cette affirmation cherche à vérifier si GPT4 va confirmer mon affirmation en interrogeant sa base d’entrainement. Dans ce cas je cherche à créer une ambiguïté avec le terme « présidente« .

La réponse de GPT4 est correcte malgré l’ambiguïté dans mon affirmation. L’ambiguïté réside dans le fait que Simone Veil a été présidente du parlement Européen. Ainsi, si GPT avait analysé que le terme de ma phrase « présidente » il aurait pu déclarer que Simone Veil avait été « présidente de la République Française« .
Cet exemple montre que son traitement statistique a privilégié d’associer au terme « présidente » la mention « Présidente du parlement Européen« .
Si je prends cet exemple c’est qu’au début de l’année 2023, GPT faisait l’erreur d’associer la personnalité de Simone Veil à la fonction de présidente de la République Française. Dans ce cas, c’est un biais que l’on nomme « hallucination ».

Les modèles de langage comme GPT-4 et plus généralement l’intelligence artificielle (IA) peuvent présenter plusieurs types de biais, qui sont souvent le reflet des données sur lesquelles ils ont été entraînés.
Il faut préciser que dans le cas de GPT nous n’avons pas accès aux données d’entrainement, ce qui signifie que nous n’avons aucun contrôle des données d’entrainement !…
Les biais du modèle de langage GPT
Ces biais peuvent affecter la façon dont l’IA interprète les informations et génère des réponses.
Ce qu’il faut retenir : La qualité de la donnée minimise les biais.
Voici quelques exemples :
Biais de confirmation : Tendance à favoriser les informations qui confirment les croyances existantes dans les données d’entraînement. Par exemple, si un modèle a été plus fréquemment exposé à certaines opinions ou perspectives, il pourrait générer des réponses qui penchent indûment vers ces points de vue.
Exemple : Si un utilisateur demande à GPT-4 si le vin rouge est meilleur pour la santé que le vin blanc, et que les données d’entraînement contiennent plus d’articles affirmant cette idée, le modèle pourrait générer une réponse qui confirme cette croyance, même si elle n’est scientifiquement prouvée. (Cet exemple croise un bien de confirmation et un biais d’hallucination, le vin rouge comme le vin blanc n’est pas bénéfique pour la santé… le vin rouge est peut être meilleur au goût que le vin blanc ?)
Biais de genre et de race : L’IA peut reproduire des stéréotypes de genre ou de race. Par exemple, associer des professions ou des rôles à un genre ou une race spécifique, basé sur les déséquilibres ou les représentations stéréotypées présentes dans les données d’entraînement.
Exemple : « Le médecin est un homme, l’infirmière est une femme« , reflète un biais de genre. Ce type de biais se produit lorsque l’IA renforce des stéréotypes sociaux ou culturels, dans ce cas, des stéréotypes de genre liés aux professions.
Biais d’hallucination : Il s’agit de la tendance à générer des informations fausses ou non fondées.
Exemple : Si on demande à GPT qui était le président français en 1985, il pourrait répondre incorrectement avec un nom fictif ou historiquement inexact, comme « Jean Dupont« , en se basant sur des associations erronées.
Biais de sélection des données : Ce biais survient lorsque les données d’entraînement ne représentent pas équitablement tous les groupes ou perspectives, conduisant le modèle à sous-performer ou à être moins précis pour certains groupes ou sujets.
Exemple : Imaginons une institution financière développant un système d’IA pour évaluer la solvabilité des clients et décider de leur accorder ou non des crédits. Si l’ensemble de données utilisé pour entraîner ce système est principalement composé d’informations sur des clients d’un certain groupe socio-économique (par exemple, majoritairement des personnes à revenu élevé), le modèle peut développer un biais.
Biais de popularité : Les modèles peuvent avoir tendance à privilégier des idées, des perspectives ou des sujets qui sont plus fréquemment discutés ou populaires dans les données d’entraînement, ce qui peut mener à une sous-représentation de points de vue moins populaires ou minoritaires.
Exemple : En demandant des informations sur un musicien français, GPT pourrait privilégier des artistes populaires et contemporains, au détriment de musiciens classiques ou moins connus.
Biais contextuel ou temporel : Les modèles peuvent ne pas comprendre correctement le contexte actuel ou les changements temporels, en s’appuyant sur des données qui peuvent être obsolètes ou ne pas refléter l’état actuel des connaissances.
Exemple : Si on interroge le modèle sur les opinions actuelles en France concernant le nucléaire, il pourrait fournir des réponses basées sur des données plus anciennes, ne reflétant pas les changements récents dans l’opinion publique ou la politique.
Biais d’amplification : L’IA peut amplifier des préjugés subtils présents dans les données d’entraînement, les rendant plus prononcés dans les réponses générées.
Exemple : Lors d’une discussion sur les régions viticoles françaises, le modèle pourrait exagérer les stéréotypes associés à certaines régions, comme la supériorité des vins de Bordeaux, amplifiant une préférence qui n’est pas nécessairement aussi prononcé dans la réalité.
La Base d’entraînement de ChatGPT
La base d’entraînement repose sur une large collection de textes provenant de diverses sources. Il faut retenir que GPT est dans l’incapacité d’apprendre en temps réel.
GPT (3.5 et v4) ne sait pas apprendre en temps réel. Cela signifie que l’utilisateur doit se référer à la dernière mise à jour du modèle de langage pour évaluer son degré d’apprentissage. Toutefois avec l’arrivée des GPTs il est possible de construire un modèle de langage personnalisé notamment en lui donnant des instructions précises et des documents (textes).
Cette évolution date de novembre 2023 et on manque de recul pour mesurer à quel point les instructions et les données intégrées dans ces (mini)GPT(spécialisés) fonctionnent (mieux) que la version standard de GPT-4.
Conclusion
GPT est une innovation technologique qui surprend par sa vitesse de diffusion et d’appropriation. Une étude publiée dans le Journal Le Monde annonce que 55% des étudiants ont déjà eu recours à ChatGPT dans le cadre de leur production de mémoire d’étude… sans même savoir réellement comment cette technologie fonctionne.
Une vérité indéniable est que ChatGPT représente une véritable révolution, semblable à un « big bang », dans le monde des intelligences artificielles génératives mais également dans le monde universitaire qui va devoir repenser les évaluations des étudiants.






Laisser un commentaire