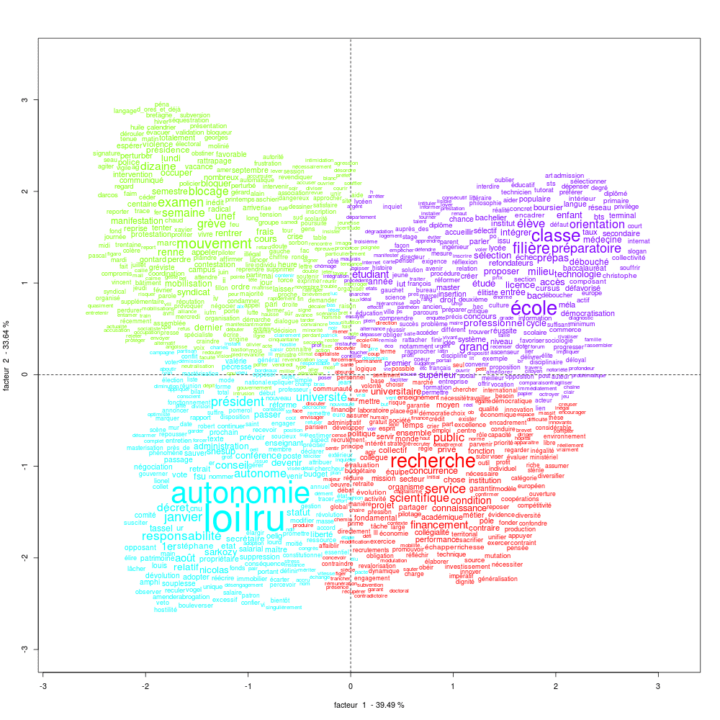
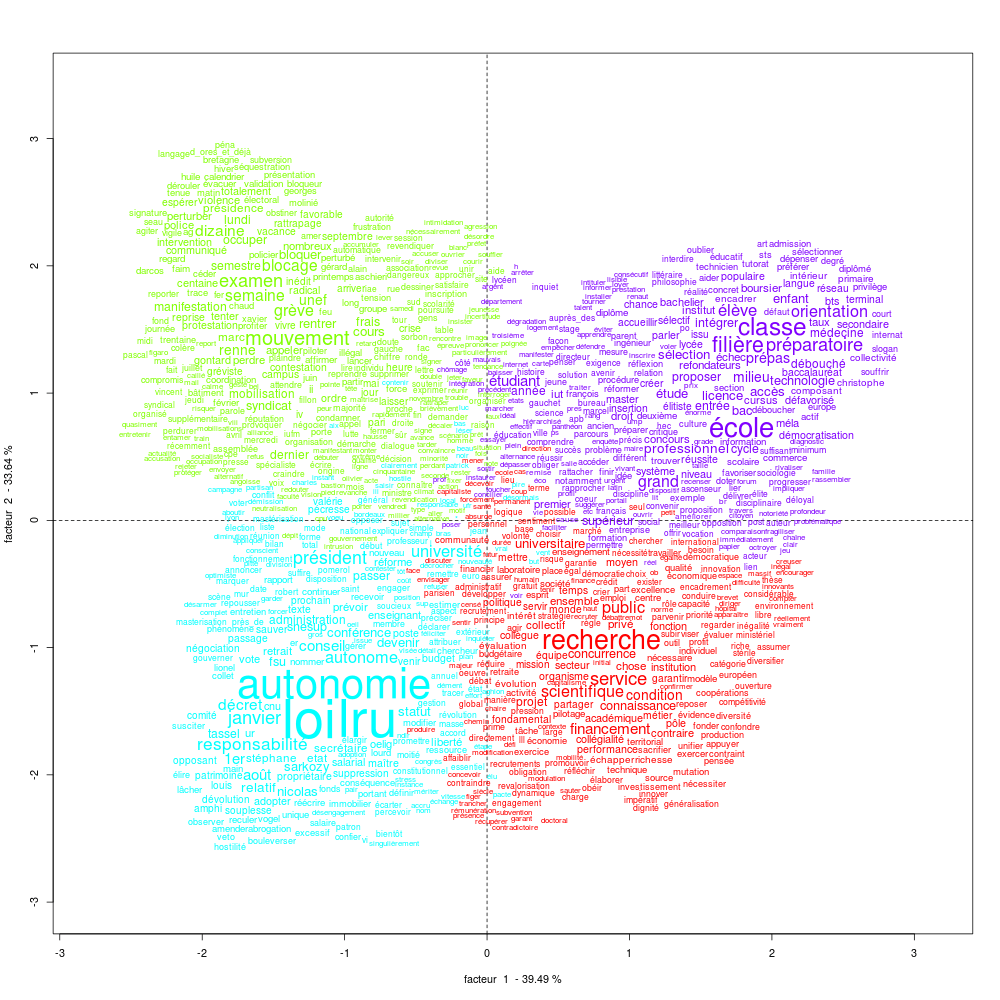
Et voici ce que nous allons obtenir après avoir lancé le script :
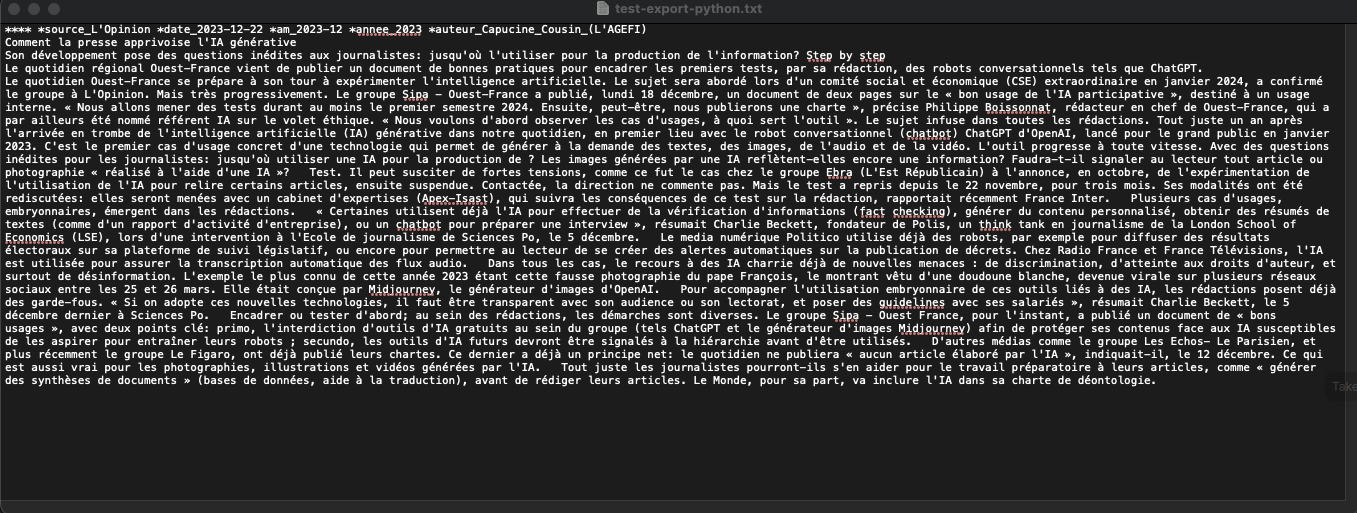
Le script nettoie les principales balises inutiles et incompatibles avec le format attendu pour le logiciel IRAMUTEQ.
Le résultat nécessitera un dernier nettoyage (rechercher / remplacer) dans votre éditeur de texte préféré 😉
Comment fonctionne le script ?
On cherche à formater les balises inutiles qui n’ont pas été supprimées, notamment en placant les variables « * » sur la première ligne.
La première ligne doit avoir un format très précis : **** *variable_nomdujournal *date *annéemois *année *auteur
**** *source_L’Opinion *date_2023-12-22 *am_2023-12 *annee_2023 *auteur_Capucine_Cousin_(L’AGEFI)
Si toutefois vous ne souhaitez pas afficher l’auteur de l’article il est tout à fait possible de le supprimer.
Dans ce script j’ai choisi de d’afficher cette variable. Elle pose toutefois un problème dans un corpus contenant plusieurs articles car le nom de l’auteur selon le journal ne figure pas dans la même balise.
# Concaténer les informations en première ligne
info_debut = f"**** {nom_journal_formate} {date_formattee} {am_formattee} {annee_formattee} {auteur_formate}\n"
# Supprimer les lignes vides et ajouter la première ligne avec les variables
lignes = [ligne for ligne in texte.splitlines() if ligne.strip()]
texte_sans_lignes_vides = info_debut + '\n'.join(lignes)
with open(chemin_txt, 'w', encoding='utf-8') as fichier_txt:
fichier_txt.write(texte_sans_lignes_vides)
Le Script magique !
Voici le script complet et prêt à l’emploi.
J’espère qu’il vous sera utile pour traiter votre corpus, même si pour l’instant il est limité à un seul article.
Le but de ce script est de réduire autant que possible le travail manuel de formatage. Cependant, vous aurez encore besoin d’effectuer certaines tâches de base, comme utiliser la fonction rechercher/remplacer pour éliminer les doubles espaces ou recoder certains éléments avec des underscores.
from bs4 import BeautifulSoup
import os
import re
import html
from datetime import datetime
import locale
# Définir la locale pour interpréter les dates en français
locale.setlocale(locale.LC_TIME, 'fr_FR') # ou 'fr_FR.utf8'
def extraire_texte_html(chemin_html, chemin_txt):
with open(chemin_html, 'r', encoding='utf-8') as fichier:
contenu_html = fichier.read()
soup = BeautifulSoup(contenu_html, 'html.parser')
# Supprimer la balise <head> et son contenu
if soup.head:
soup.head.decompose()
# Rechercher et supprimer spécifiquement la balise <div> contenant "AUTRE"
divs_autre = soup.find_all("div")
for div in divs_autre:
if div.find("p", string=re.compile("AUTRE")):
div.decompose()
# Extraire le nom du journal
span_journal = soup.find("span", class_="DocPublicationName")
nom_journal = span_journal.get_text(strip=True) if span_journal else ""
nom_journal_formate = f"*source_{nom_journal}"
if span_journal:
span_journal.decompose()
# Extraire la date
span_date = soup.find("span", class_="DocHeader")
date_texte = html.unescape(span_date.get_text()) if span_date else ""
span_date.decompose()
# Formatage de la date
match = re.search(r'\d{1,2} \w+ \d{4}', date_texte)
date_formattee = am_formattee = annee_formattee = ""
if match:
date_str = match.group()
try:
date_obj = datetime.strptime(date_str, '%d %B %Y')
date_formattee = date_obj.strftime('*date_%Y-%m-%d')
am_formattee = date_obj.strftime('*am_%Y-%m')
annee_formattee = date_obj.strftime('*annee_%Y')
except ValueError:
pass
# Extraire l'auteur
p_auteur = soup.find("p", class_="sm-margin-bottomNews")
auteur = p_auteur.get_text(strip=True) if p_auteur else ""
# Remplacer les espaces par des underscores dans le nom de l'auteur
auteur = auteur.replace(" ", "_")
auteur_formate = f"*auteur_{auteur}"
if p_auteur:
p_auteur.decompose()
# Supprimer les autres balises spécifiques
classes_a_exclure = ["rdp__attachnews", "Doc-LegalInfo", "rdp__certificat",
"rdp__public-cert", "publiC_lblCertificatIssuedTo", "publiC-lblNodoc",
"apd-wrapper", "icon-logo-container", "AUTRE"]
for classe in classes_a_exclure:
for div in soup.find_all("div", class_=classe):
div.decompose()
# Extraire le texte restant de la page HTML
texte = soup.get_text()
# Concaténer les informations en première ligne
info_debut = f"**** {nom_journal_formate} {date_formattee} {am_formattee} {annee_formattee} {auteur_formate}\n"
# Supprimer les lignes vides et ajouter la première ligne avec les variables
lignes = [ligne for ligne in texte.splitlines() if ligne.strip()]
texte_sans_lignes_vides = info_debut + '\n'.join(lignes)
with open(chemin_txt, 'w', encoding='utf-8') as fichier_txt:
fichier_txt.write(texte_sans_lignes_vides)
# Exemple d'utilisation
chemin_html = 'chemin/vers/votre/fichier.html' # Remplacez par le chemin de votre fichier HTML
chemin_txt = 'chemin/vers/votre/fichier.txt' # Remplacez par le chemin où vous voulez enregistrer le fichier texte
extraire_texte_html(chemin_html, chemin_txt)
Conclusion
En conclusion, ce script est actuellement optimisé pour traiter un seul article à la fois. Si vous l’exécutez sur un fichier HTML contenant plusieurs articles, seul le premier sera formaté conformément aux exigences d’IRAMUTEQ.
Cette version sert de test initial pour valider le fonctionnement du script. Des améliorations sont prévues, notamment l’ajout de boucles Python pour étendre automatiquement le traitement à l’ensemble des articles présents dans un fichier.
Ces développements feront l’objet d’un futur article.
En attendant, je vous invite à expérimenter avec ce script et à partager vos retours et suggestions, qui seront très appréciés et contribueront à l’amélioration de cet outil.
[…] Installation de BeautifulSoup4 : Cette bibliothèque est indispensable pour le fonctionnement du script (cf article). […]
[…] commencer, assurez-vous de disposer d’un environnement Python 3 sur votre machine. Ensuite, installez la bibliothèque BeautifulSoup4 en utilisant la commande pip install […]